背景 目前公司业务高速发展,各种业务数据呈井喷的态势,单表数据量急剧膨胀,随之而来是单表读写性能和吞吐量呈下降趋势而且无法应对业务高速增长产生的数据。因此需要使用分库分表机制保证高性能同时支撑和驱动业务发展,选择一款功能强大支持分库分表的中间件就成为当务之急。开源的数据库中间件众多,需要从中挑选一个适合的,并能作为映客长期演进的中间件,因此需要从多个维度对中间件进行相关测试。
分库分表方案 针对数据量过大出现的性能问题,通过分库分表将数据量保持在阀值以下,可以有效分散高并发量和缓解大数据量。
分库分表一般分垂直拆分和水平拆分,根据业务将单库(表)拆分为多库(表),常用的字段和不常用的字段拆分至不同的库(表)中,可适当缓解并发量和数据量,但不能根治;垂直拆分之后依然超过单节点所能承载的阈值,则需要水平拆分来进一步处理。 水平拆分则是根据分片算法将一个库(表)拆分为多个库(表)。
分表虽然可以解决海量数据导致的性能问题,但无法解决过多请求访问同一数据库,导致其响应变慢的问题。所以水平拆分通常要采取分库的方式(合理的配合使用分库+分表),一并解决数据量和访问量巨大的问题。
分库分表问题
事物问题
解决方案:分布式事物(缺点:随着分片数量越来越多,性能代价越来越大)
跨库跨表的join问题
解决方案:解决这一问题的普遍做法是分两次查询实现。在第一次查询的结果集中找出关联数据的id,根据这些id发起第二次请求得到关联数据。
跨库跨表的count,order by,group by以及聚合函数问题
解决方案:与解决跨节点join问题的类似,分别在各个节点上得到结果后在应用程序端进行合并。和join不同的是每个结点的查询可以并行执行,因此很多时候它的速度要比单一大表快很多。但如果结果集很大,对应用程序内存的消耗是一个问题。
数据迁移,扩容等问题
解决方案:目前业务没有比较成熟的方案
分布式主键问题
解决方案:UUID、Snowflake、数据库序列等
分库/分表策略 分库/分表维度确定后,一般常用有两种方式:
根据数值范围,比如用户Id为1-9999的记录分到第一个库,10000-20000的分到第二个库,以此类推。
根据数值取模,比如用户Id mod n,余数为0的记录放到第一个库,余数为1的放到第二个库,以此类推。
优劣比较
对比点
范围
取模
库数量
库数量前期数目比较小,可以随用户/业务按需增长
前期即根据mode因子确定库数量,数目一般比较大
扩容
调整库数量比较容易,一般只需为新用户增加库
需要数据迁移
热点数据
有单库热点数据问题
无热点数据,均分数据
分库数量 分库数量首先和单库能处理的记录数有关,一般来说,Mysql 单库超过5000万条记录,DB压力就很大(当然处理能力和字段数量/访问模式/记录长度有进一步关系)。
在满足上述前提下,如果分库数量少,达不到分散存储和减轻DB性能压力的目的;如果分库的数量多,好处是每个库记录少,单库访问性能好,但对于跨多个库的访问,应用程序需要访问多个库,如果是并发模式,要消耗宝贵的线程资源;如果是串行模式,执行时间会急剧增加。
最后分库数量还直接影响硬件的投入,一般每个分库跑在单独物理机上,多一个库意味多一台设备。所以具体分多少个库,要综合评估,一般初次分库建议分4-8个库。
产品调研 调研分析后Mycat和Sharding-jdbc功能上比较稳定成熟,支持分库分表、读写分离、分布式主键等。Tidb目前整体比较新,成本方面高,稳定性方面待考察。
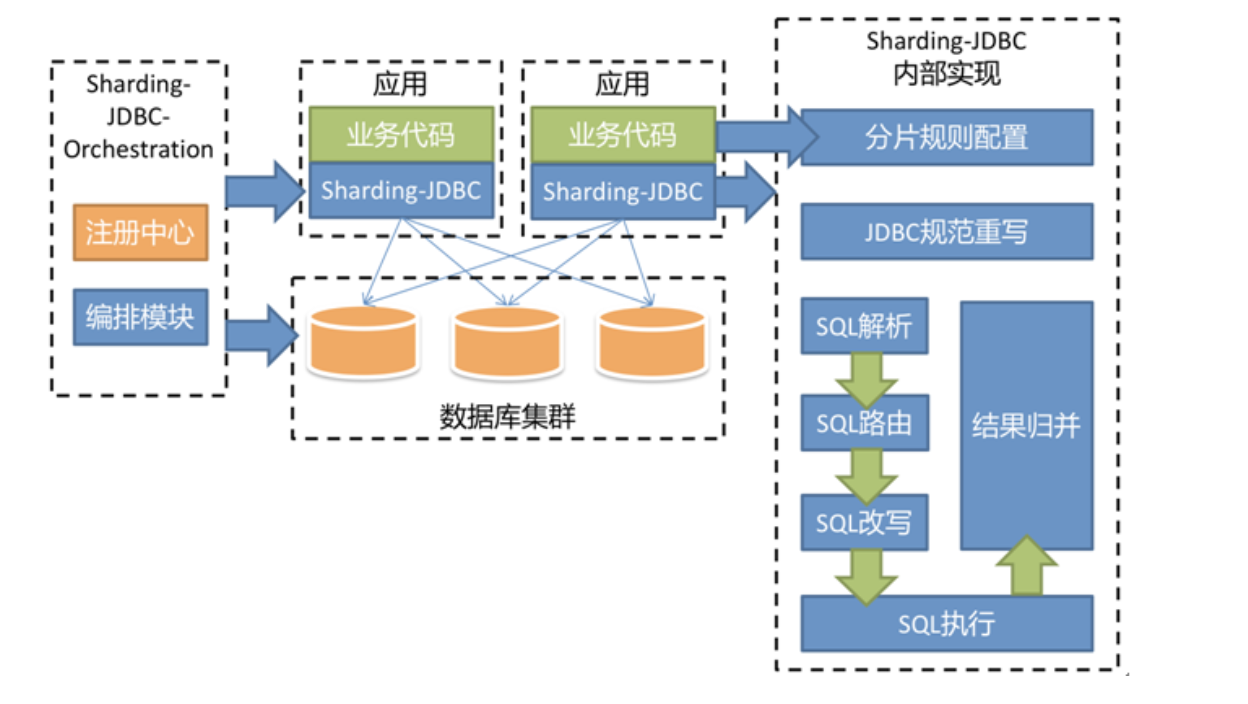
Sharding-jdbc :类似TDDL,基于JDBC协议的数据库中间件产品,使用客户端直连数据库,以jar包形式提供服务,兼容JDBC和各种ORM框架,使系统在数据访问层直接具有分片化和分布式治理的能力。
特性:
轻量级框架, 直接封装的jdbc协议,jar包形式提供服务,旧代码迁移、新代码开发成本低
无需额外部署和依赖,客户端直连数据库,无需二次转发,性能高
运维层面不改动,无需关注中间件本身的 HA
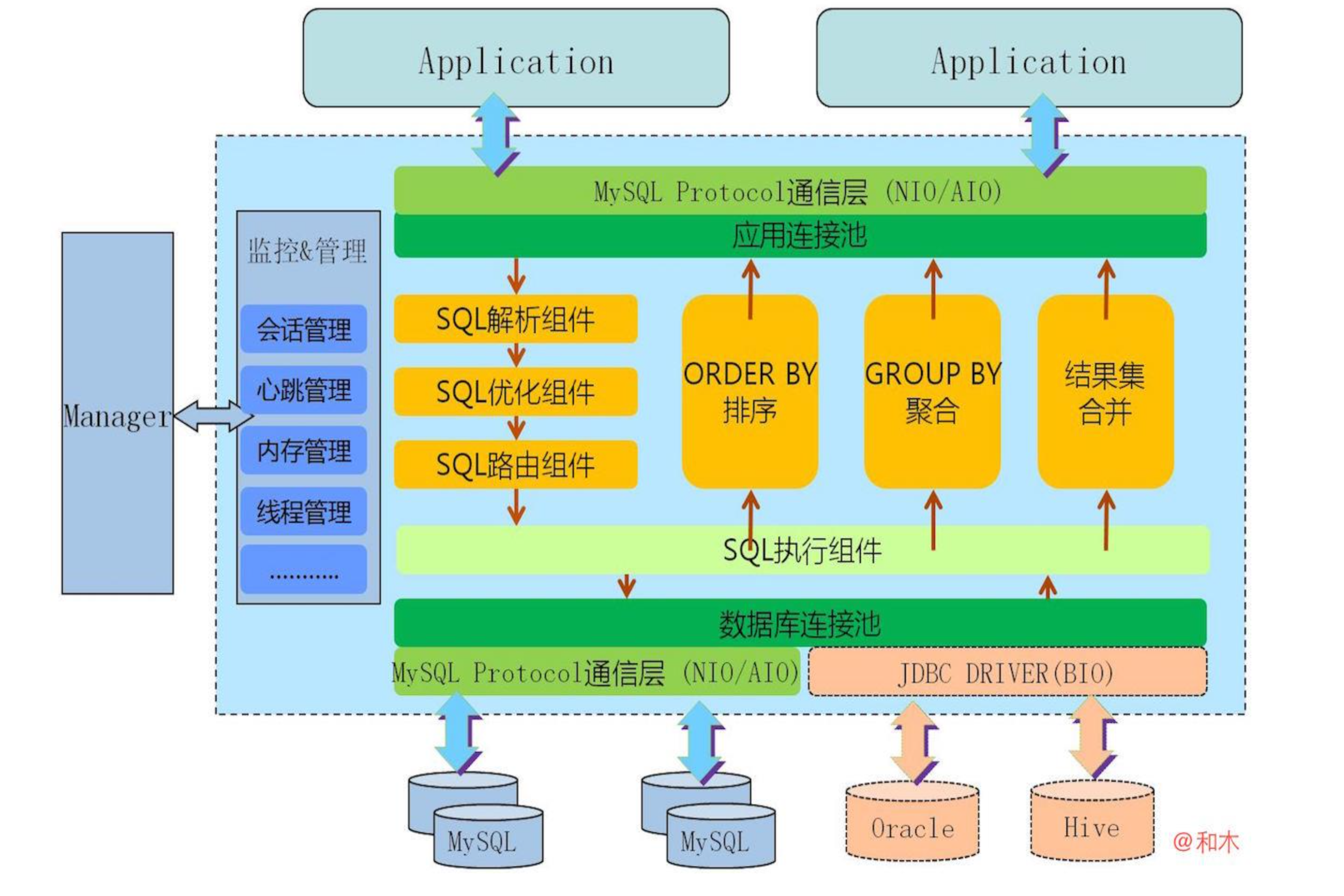
mycat :基于阿里开源的Cobar研发,对代码进行了彻底重构,使用NIO重构了网络模块,并优化了Buffer内核,增强了聚合,Join等基本特性.主要原理是拦截用户发送过来的SQL语句,对SQL语句做了特定的分析:如分
特性:
可以负责更多的内容,将数据迁移,分布式事务等纳入 Proxy 的范畴
针对mycat和mysql有较全性能监控项统计支持
可结合Storm等分布式实时流引擎,实现数据分析和数据聚合
Tidb :实现了自动的水平伸缩,强一致性的分布式事务,基于 Raft 算法的多副本复制等重要 NewSQL 特性。 TiDB 结合了 RDBMS 和 NoSQL 的优点,部署简单,在线弹性扩容和异步表结构变更不影响业务, 真正的异地多活及自动故障恢复保障数据安全,同时兼容 MySQL 协议,使迁移使用成本降到极低。
特性:
SQL支持 (TiDB 是 MySQL 兼容的)
水平线性弹性扩展
分布式事务
跨数据中心数据强一致性保证
故障自恢复的高可用
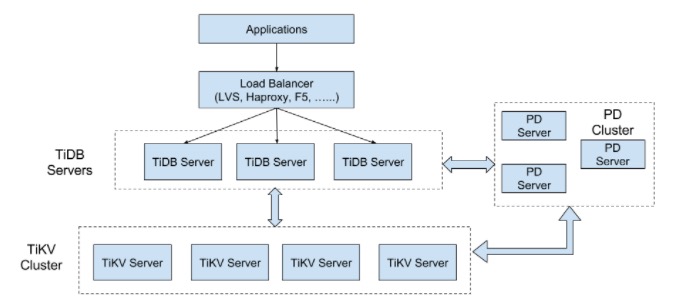
架构:
TiDB 集群主要分为三个组件:
TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。 TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个: 一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region(区域),每个 Region 负责存储一个 Key Range (从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region 。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
比较 本次对比不是对MySQL数据库进行极限或压力性能测试,而是在同等软硬件环境下对选取的数据库中间件在软件/物理架构、功能特性、扩展性、SQL支持程度、容灾/容错、可用性、可维护性、接入成本等进行综合衡量。
对比点
mycat
sharding-jdbc
Tidb
分库分表功能
支持部分分库分表(支持单库分表,多库单表,但是不支持同时多库分表)
支持
支持
读写分离功能
支持,支持读写延时切换,支持多主模式,支持心跳监测
只支持简单的读写分离
待定
分布式事物
弱XA
当前版本不支持,未来版本支持XA事物和Base事物
完全ACID
跨库跨表的join和聚合问题
支持分页、排序、分组、聚合,内部通过堆外内存计算合并
支持分页、排序、分组、聚合,内部集成内存分组归并 和流式分组归并
无
数据迁移,扩容等问题
提供迁移脚本工具(经过测试发现大数据量的时候会出现报错问题,导致迁移中断)
无
无
SQL解析
Druid解析器
自研解析器(性能高),后期规划ANTLR解析
待定
数据库连接
自研数据库连接池,存在占用连接数过大问题
SS自动选择内存限制模式和连接限制模式模式
无
数据治理
支持zk
支持zk和etcd
待定
APM监控
无
只支持sql解析和路由相关
待定
分布式主键
雪花算法、数据库序列、zk序列
雪花算法
区间分段(可能出现重复主键)
分片规则
基本支持,可自定义
基本支持,可自定义,支持多分片项
内部实现机制,无需业务制定
支持数据库
mysql、nosql(monogdb)
mysql
本身就是数据库
HA
haproxy+keeplive
无
水平扩展+高可用
语言
java
java
go
可维护性
较高(提供管控台)
较高
低(虽然提供管控台,但是由于开发语言限制与团队技术栈不一致)
接入成本
低
较高(业务方需配合)
高(业务数据需要全部迁移tidb)
社区活跃度
低
高(最近加入Apache孵化器)
高
优点
有效解决了数据库链接数多的问题,因为各工程应用只连接中间件,中间件代理了真实的物理链接,并且与后端mysql物理链接是复用型的所有的分库分表等规则集中配置在中间件上,更可控
性能高
产品较新
缺点
1.计算过程只能单节点计算,单机扩展只能调优,但是集群可以做负载均衡; 2.相对sharding-jdbc来说,由于增加一层中间代理,性能稍微降低; 3.需要保证中间件的可用性,会增加运维成本及复杂度;4.代码排查问题弱,需要熟悉mysql协议和nio相关知识;
1.业务方需要配置多数据源,分库分表走sharding数据源,其他走主数据源(目前不支持全部数据源都走sharding,由于每次sql路由都需要做sql解析,sql解析这步会检查sql的支持项);2.sharding-jdbc目前不支持分布式事物,和社区沟通,下个版本会支持XA和Base解决方案,目前只有sharding-proxy支持XA事物;3.分布式主键采用雪花算法,但是没有考虑时间回拨问题(闰秒),还有业务方需要手动设置workid(这点确实不人性化); 4.客户端业务复杂,如wechat项目
1.业务数据需要全部迁移,并且生产环境配置要求较高 2.成本高
综合考虑,shardjdbc整体优于mycat,tidb由于太过新颖,在加上成本问题,可以暂不考虑。
Mycat分库分表后不支持的sql语法
SELECT不支持的语法
不支持跨分片的交叉查询
跨节点的联合查询,不支持union all,union
mycat支持跨库2张表的join
INSERT不支持的语法
插入的字段不包含分片字段
插入的分片字段找不到对应分片
复制插入 insert into…select…
多行插入 insert into tab_a(c1,c2) values(v1,v2),(v11,v21)…
UPDATE不支持的语法
更新的列包含分片列
多表更新 update a, b set a.nation=’China’, b.pwd=’123456’ where a.id=b.id
复杂多表关联更新 update a, b set a.nation=’China’ where a.id=b.id; 但支持子查询方式 update a set a.nation=’China’ where id in (select id from b);
DELETE不支持语法
复杂删除sql delete a from a join b on a.id=b.id; 支持子查询方式 delete from a where a.id in (select id from b), 但表不能起别名
其他
Call procedure() MyCat未支持存储过程定义, 因而不允许调用存储过程,但可通过注解来调用各个分片上的存储过程
Select func(); 不支持这种方式直接调用自定义函数, 但支持 select id, func() from employee 只需employee所在的所有分片上存在这个函数。MySql自带函数可随意使用。
Sharding-Jdbc分库分表后不支持的sql语法
SQL项
不支持原因
INSERT INTO tbl_name (col1, col2, …) SELECT col1, col2, … FROM tbl_name WHERE col3 = ?
insert into … select …
INSERT INTO tbl_name SET col1 = ?
insert … set …
SELECT DISTINCT * FROM tbl_name WHERE column1 = ?
distince
SELECT COUNT(col1) as count_alias FROM tbl_name GROUP BY col1 HAVING count_alias > ?
having
SELECT * FROM tbl_name1 UNION SELECT * FROM tbl_name2
union
SELECT * FROM tbl_name1 UNION ALL SELECT * FROM tbl_name2
union all
SELECT * FROM tbl_name1 WHERE (val1=?) AND (val1=?)
只支持一级冗余括号
SELECT * FROM ds.tbl_name1
不支持seheme
mycat 使用教程 mycat分库分表规则主要是修改server.xml、schema.xml和rule.xml。
server.xml:是Mycat服务器参数调整和用户授权的配置文件。
schema.xml:是逻辑库定义和表以及分片定义的配置文件。
rule.xml:是分片规则的配置文件,分片规则的具体一些参数信息单独存放为文件,也在这个目录下,配置文件修改需要重启MyCAT。
mycat服务端server.xml配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 <mycat:server xmlns:mycat ="http://io.mycat/" > <system > <property name ="nonePasswordLogin" > 0</property > <property name ="useSqlStat" > 0</property > <property name ="useGlobleTableCheck" > 0</property > <property name ="sequnceHandlerType" > 2</property > <property name ="processorBufferPoolType" > 0</property > <property name ="handleDistributedTransactions" > 0</property > <property name ="useOffHeapForMerge" > 1</property > <property name ="memoryPageSize" > 64k</property > <property name ="spillsFileBufferSize" > 1k</property > <property name ="useStreamOutput" > 0</property > <property name ="systemReserveMemorySize" > 384m</property > <property name ="useZKSwitch" > false</property > <property name ="serverPort" > 3307</property > <property name ="managerPort" > 9066</property > </system > <user name ="root" defaultAccount ="true" > <property name ="password" > 123456</property > <property name ="schemas" > dbtest</property > <property name ="readOnly" > true</property > <property name ="benchmark" > 11111</property > <property name ="usingDecrypt" > 1</property > </user > </mycat:server >
分库分表schema.xml配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 <mycat:schema xmlns:mycat ="http://io.mycat/" > <schema name ="dbtest" checkSQLschema ="true" sqlMaxLimit ="100" > <table name ="travelrecord" dataNode ="dn1,dn2" primaryKey ="id" rule ="rule1" > </table > </schema > <dataNode name ="dn1" dataHost ="localhost1" database ="db01" /> <dataNode name ="dn2" dataHost ="localhost1" database ="db02" /> <dataHost name ="localhost1" maxCon ="1000" minCon ="10" balance ="0" writeType ="0" dbType ="mysql" dbDriver ="native" switchType ="1" slaveThreshold ="100" > <heartbeat > select user()</heartbeat > <writeHost host ="hostM1" url ="127.0.0.1:3306" user ="root" password ="123456" > </writeHost > </dataHost > </mycat:schema >
分库分表规则rule.xml配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 <mycat:rule xmlns:mycat ="http://io.mycat/" > <tableRule name ="rule1" > <rule > <columns > id</columns > <algorithm > func1</algorithm > </rule > </tableRule > <function name ="func1" class ="io.mycat.route.function.PartitionByLong" > <property name ="partitionCount" > 2</property > <property name ="partitionLength" > 512</property > </function > </mycat:rule >
sharding-jdbc 使用教程
maven依赖包1 2 3 4 5 <dependency> <groupId>io.shardingsphere</groupId> <artifactId>sharding-jdbc</artifactId> <version>${sharding-sphere.version}</version> </dependency>