JVM学习笔记
JVM内存结构
根据《Java虚拟机规范(Java SE 7版)》规定,Java虚拟机内存结构可划分为以下区域:
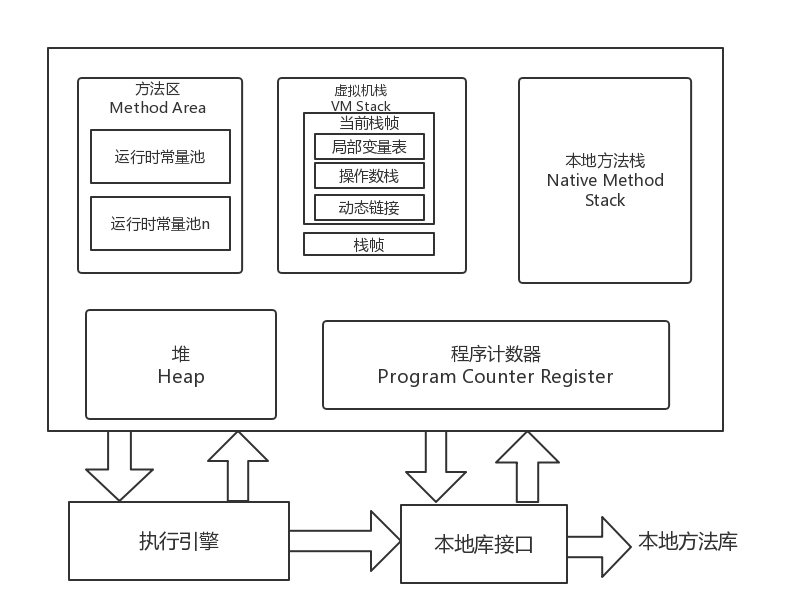
程序计数器:
- 程序计数器是一块较小的内存空间,可看作是当前线程所执行的字节码的行号指示器。在虚拟机概念模型里,字节码解释器工作时就是通过改变该计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖该计数器来完成。
- JVM中多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的。即在任何时刻,CPU只会执行一条线程中的指令,因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各线程之间计数器互不影响,独立存储,该内存为线程私有。
- 如果线程正在执行一个Java方法,则PC记录的是正在执行的虚拟机字节码指令的地址,如果正在执行的是Native方法,则PC值为Undefined,该内存区域是唯一一个没用OOM的区域。
虚拟机栈:
- Java虚拟机栈也是线程私有的,它的生命周期与线程相同。虚拟机栈描述的是Java方法执行的内存模型:每个方法在执行的时候会创建一个栈帧,用来存储局部变量表、操作数栈、动态链接、方法出口等信息。每个方法从调用至执行完成的过程对应着一个栈帧在虚拟机栈中入栈到出栈的过程.
- 局部变量表:存放编译期可知的各种基本数据类型(如Boolean、byte、char、short、int、float、long、double)、对象引用类型(如:引用指针、句柄等)。局部变量表所需内存空间在编译期间完成分配,即进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是确定的,在方法运行期间不会改变局部变量表的大小。
- 异常情况:
- StackOverflowError异常:线程请求的栈深度大于虚拟机所允许的深度时,会抛出栈上溢异常
- OutOfMemoryError异常:虚拟机栈动态扩展时无法申请到足够的内存,会抛出内存溢出异常
本地方法栈:
- 发挥的作用与虚拟机栈类似,区别在于虚拟机栈为虚拟机执行Java方法(字节码)服务,而本地方法栈则是为虚拟机使用到的Native方法服务,如Java访问C语言的方法、汇编程序等。
- 异常情况:与虚拟机栈一样。
堆:
- 堆是Java所管理的内存中最大的一块,是被所有线程共享的一块内存区域,在虚拟机启动时创建,用于存放对象实例,也是垃圾收集器管理的主要区域。
- 根据GC分代收集算法,堆可细分为:新生代和老年代;新生代又分为Eden区、Survivor区(from,to)从内存分配的角度看,线程共享的Java堆可划分出多个线程私有的分配缓冲区(TLAB:Thread Local Allocation Buffer)
- 堆内存仅要逻辑上连续即可,物理上不连续也可以,如果在堆中没有内存完成实例分配。并且堆也无法再扩展时,则会抛出OOM异常
方法区:
- 与堆一样,方法区是各线程共享的,用于存储已被虚拟机 加载的类信息、常量、静态变量、即时编译器编译后的代码等数据
- 对于开发者来说,该区又称为“永久代”Permanent Generation,当方法区无法满足内存分配时,将抛出OOM异常