otter简介
Otter的业务域是支持异构数据库实时同步,数据记录变更订阅服务。
Otter需要保障数据库的事务一致性,包括DDL(表结构变更)也可以进行同步或过滤。而DBA天生就在这个坑里,绝对不能让主备不一致、或事务不完整,哪怕只是一条数据。而且DBA迫切希望以后不用通知下游了,让DRC自动适配主备切换或拆库。
定位:基于数据库增量日志解析,准实时同步到本机房或异地机房的mysql/oracle数据库.一个分布式数据库同步系统.
Otter具备的三大特性:
- 1)稳定性,支持HA;
- 2)实时性;
- 3)一致性,数据同步前后必须保证数据的一致性;
我们公司对Otter的需求场景:
- MySQL原生复制
- 大数据实时抽取
- 搜索实时索引
- 数据迁移
Otter架构
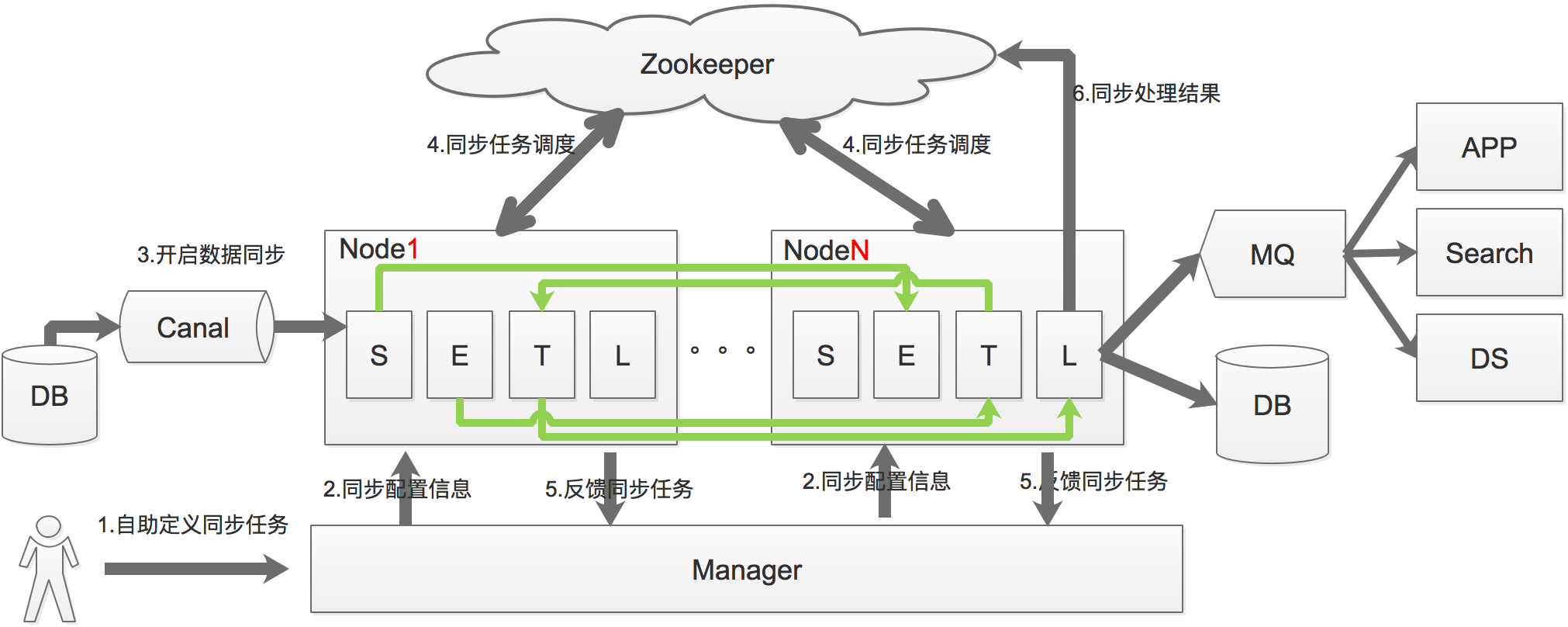
数据同步过程可以分为Select–>Extract、Transform–>Load四个过程,也就是上图中的S、E、T、L,通过将这4个步骤进行服务拆分,每个服务都具有自己的线程池。通过S、L过程的串型,保证数据的一致性,E、T过程的并行提升系统处理的性能。
原理:
基于Canal开源产品,获取数据库增量日志数据。
典型管理系统架构,manager(web管理)+node(工作节点)
a. manager运行时推送同步配置到node节点;
b. node节点将同步状态反馈到manager上;
基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作.
功能改造
分库分表支持
原生的otter是不支持分库分表场景的,分库分表已经不属于Otter数据同步业务领域,但是分库分表的支持又是绝大多数功能数据同步不可避免的。
我们公司业务在改造过程中,涉及到以下需求:
- 支持分库场景;
- 支持分表场景;
- 支持分库分表场景;
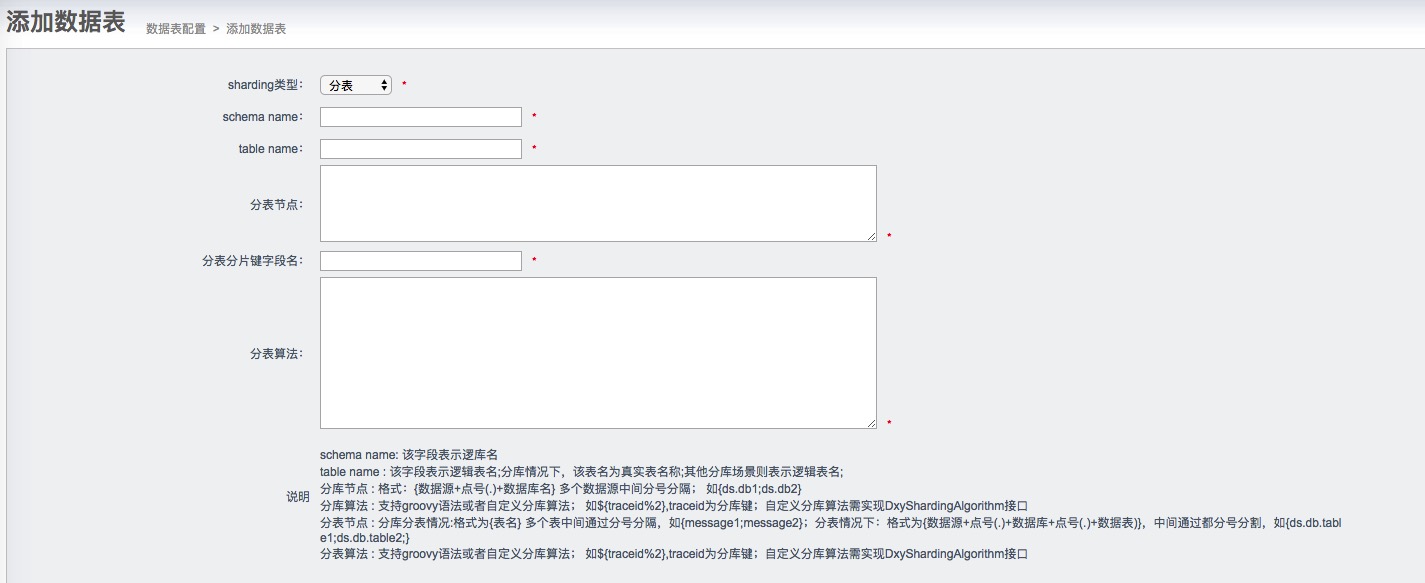
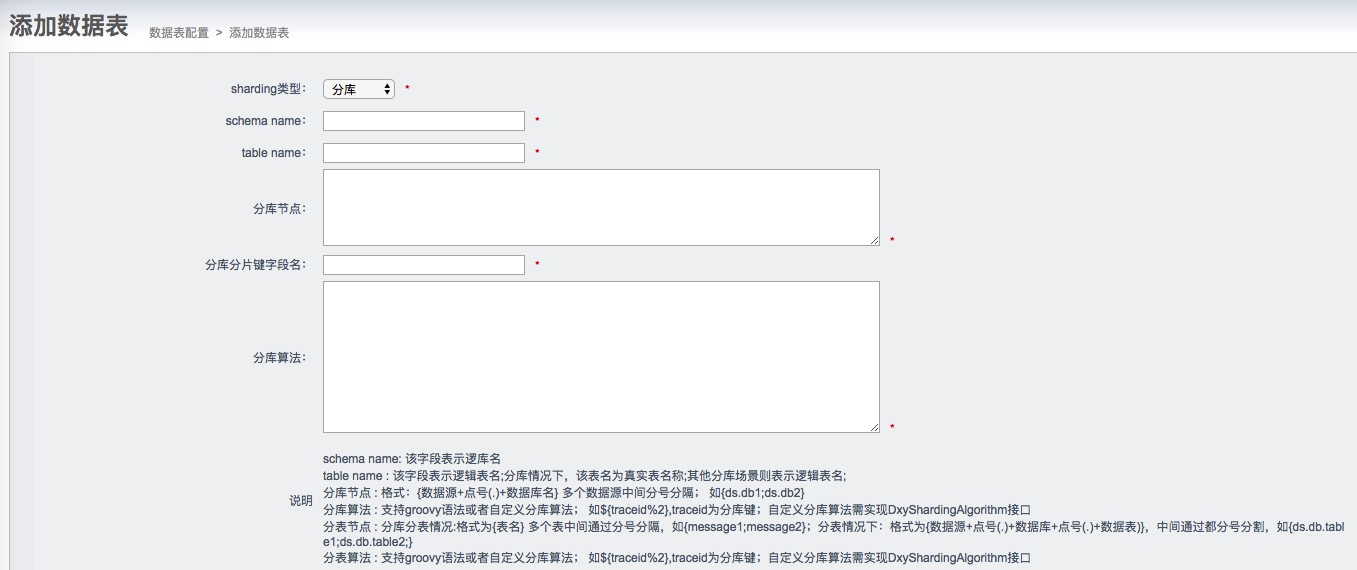
- 分片算法支持简单取模算法;
- 分片支持自定义算法,只需要实现DxyShardingAlgorithm接口即可;
我们是在DataMedia上做扩展的,增加了分片类型、分片字段和分片算法字段。
分库分表:
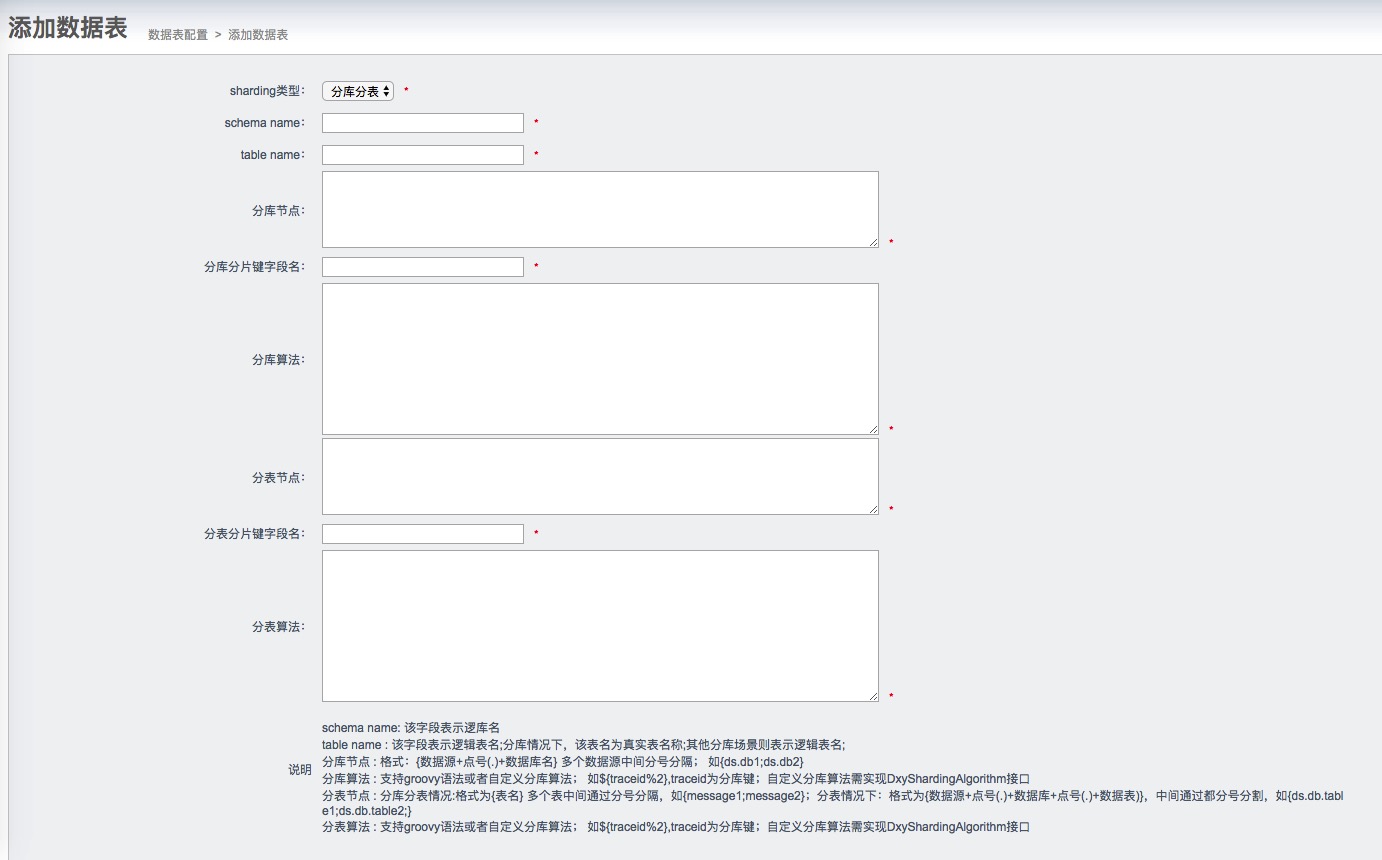
分表:
分库:
改造点
1).在Transform阶段进行了扩展,当目标数据表配置为分库分表时候,这时候会加载最终目标数据表的路由;
2).当eventdata不包含分片字段导致无法确定分片路由,我们将会为每个分片拷贝eventdata,解决多路拷贝分发;
3).多路拷贝情况下,针对多库多表,增加库表验证防止库表不一致路由问题;
4).在Extract阶段,针对数据库反查数据为空的情况,去除反查为null列(问题:通道同步模式为列模式,先插入数据,然后更新数据,最后删除数据,otter在Extract阶段会反查数据库查询未更新的列,此时该数据已删除,造成生成sql中出现null列);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
|
public ShardingCalDTO sharingCalculate(EventData result, DataMedia targerDataMedia){
ShardingCalDTO shardingCalDTO = new ShardingCalDTO();
List<ShardingCalDTO.ShardingDSDTO> list = new ArrayList<ShardingCalDTO.ShardingDSDTO>();
shardingCalDTO.setShardingDSDTOList(list);
if(targerDataMedia.getShardingType().intValue() != ShardingTypeEnum.NORMAL.getCode()){
DbMediaSource dbDataMediaSource = null;
String schema = "";
String table = "";
List<DbMediaSource> sharingDataSources = targerDataMedia.getShardingDBSources();
Assert.assertNotNull(sharingDataSources);
Map<String,DbMediaSource> dbMediaSourcemap = new HashMap<String,DbMediaSource>(sharingDataSources.size());
Map<String, EventColumn> columnMap = new HashMap<String, EventColumn>();
for(DbMediaSource dbMediaSource:sharingDataSources){
dbMediaSourcemap.put(dbMediaSource.getName(),dbMediaSource);
}
if(null != result.getKeys() && 0 != result.getKeys().size()){
for(EventColumn eventColumn:result.getKeys()){
columnMap.put(eventColumn.getColumnName(),eventColumn);
}
}
if(null != result.getColumns() && 0 != result.getColumns().size()){
columnMap.put(eventColumn.getColumnName(),eventColumn);
}
}
if(result.getEventType() == EventType.INSERT && null == columnMap.get(targerDataMedia.getShardingDBColumn()) &&
null == columnMap.get(targerDataMedia.getShardingTableColumn())){
shardingCalDTO.setSkip(true);
LOGGER.error("插入语句不存在分片键,跳过 eventdate:{}",result.toString());
return shardingCalDTO;
}
if(targerDataMedia.getShardingType().intValue() == ShardingTypeEnum.SHARDING_TABLE.getCode()){
List<ShardingTableDTO> shardingTableDTOs = targerDataMedia.getShardingTableDTOS();
Assert.assertNotNull(shardingTableDTOs);
EventColumn eventColumn = columnMap.get(targerDataMedia.getShardingTableColumn());
if(null == eventColumn || null == eventColumn.getColumnValue()){
for(ShardingTableDTO shardingTableDTO:shardingTableDTOs){
ShardingCalDTO.ShardingDSDTO shardingDSDTO = shardingCalDTO.new ShardingDSDTO();
shardingDSDTO.setShardingDbMediaSource(dbMediaSourcemap.get(shardingTableDTO.getDsName()));
shardingDSDTO.setShardingScheme(shardingTableDTO.getDbName());
shardingDSDTO.setShardingTabele(shardingTableDTO.getTableName());
list.add(shardingDSDTO);
}
}else{
dbDataMediaSource = dbMediaSourcemap.get(shardingTableDTOs.get(0).getDsName());
schema = shardingTableDTOs.get(0).getDbName();
ShardingTableDTO shardingTableDTOResult = shardingStrategyFactory.getSharingStrategy(shardingTableDTOs,targerDataMedia.getShardingTableAlgorithm(),
targerDataMedia.getShardingTableColumn(), eventColumn.getColumnValue());
table = shardingTableDTOResult.getTableName();
}
}else{
List<ShardingDBDTO> shardingDBDTOS = targerDataMedia.getShardingDBDTOS();
EventColumn dbColumn = columnMap.get(targerDataMedia.getShardingDBColumn());
if(null != dbColumn && null != dbColumn.getColumnValue()){
ShardingDBDTO shardingDBDTO = shardingStrategyFactory.getSharingStrategy(shardingDBDTOS,targerDataMedia.getShardingDBAlgorithm(),
targerDataMedia.getShardingDBColumn(), dbColumn.getColumnValue());
dbDataMediaSource = dbMediaSourcemap.get(shardingDBDTO.getDsName());
schema = shardingDBDTO.getDbName();
if(targerDataMedia.getShardingType().intValue() == ShardingTypeEnum.SHARDING_DB_TABLE.getCode()) {
List<ShardingTableDTO> shardingTableDTOs = targerDataMedia.getShardingTableDTOS();
EventColumn tableColumn = columnMap.get(targerDataMedia.getShardingTableColumn());
if(null == tableColumn || null == tableColumn.getColumnValue()) {
for(ShardingTableDTO shardingTableDTO:shardingTableDTOs){
ShardingCalDTO.ShardingDSDTO shardingDSDTO = shardingCalDTO.new ShardingDSDTO();
shardingDSDTO.setShardingDbMediaSource(dbMediaSourcemap.get(shardingDBDTO.getDsName()));
shardingDSDTO.setShardingScheme(shardingDBDTO.getDbName());
shardingDSDTO.setShardingTabele(shardingTableDTO.getTableName());
list.add(shardingDSDTO);
}
}else{
ShardingTableDTO shardingTableDTO= shardingStrategyFactory.getSharingStrategy(shardingTableDTOs,targerDataMedia.getShardingTableAlgorithm(),
targerDataMedia.getShardingTableColumn(), tableColumn.getColumnValue());
table = shardingTableDTO.getTableName();
}
}else if(targerDataMedia.getShardingType().intValue() == ShardingTypeEnum.SHARDING_DB.getCode()) {
table = targerDataMedia.getName();
}
}else{
if(targerDataMedia.getShardingType().intValue() == ShardingTypeEnum.SHARDING_DB_TABLE.getCode()) {
List<ShardingTableDTO> shardingTableDTOs = targerDataMedia.getShardingTableDTOS();
for(ShardingDBDTO shardingDBDTO:shardingDBDTOS){
for(ShardingTableDTO shardingTableDTO:shardingTableDTOs){
if(!shardingDBDTO.getAvaliableTabelName().contains(shardingTableDTO.getTableName())){
LOGGER.warn("跳过该表名:{} eventData:{}",shardingTableDTO.getTableName(),result.toString());
continue;
}
ShardingCalDTO.ShardingDSDTO shardingDSDTO = shardingCalDTO.new ShardingDSDTO();
shardingDSDTO.setShardingDbMediaSource(dbMediaSourcemap.get(shardingDBDTO.getDsName()));
shardingDSDTO.setShardingScheme(shardingDBDTO.getDbName());
shardingDSDTO.setShardingTabele(shardingTableDTO.getTableName());
list.add(shardingDSDTO);
}
}
}else if(targerDataMedia.getShardingType().intValue() == ShardingTypeEnum.SHARDING_DB.getCode()){
for(ShardingDBDTO shardingDBDTO:shardingDBDTOS){
ShardingCalDTO.ShardingDSDTO shardingDSDTO = shardingCalDTO.new ShardingDSDTO();
shardingDSDTO.setShardingDbMediaSource(dbMediaSourcemap.get(shardingDBDTO.getDsName()));
shardingDSDTO.setShardingScheme(shardingDBDTO.getDbName());
shardingDSDTO.setShardingTabele(targerDataMedia.getName());
list.add(shardingDSDTO);
}
}
}
}
if(null != dbDataMediaSource && StringUtils.isNotEmpty(schema) && StringUtils.isNotEmpty(table)){
ShardingCalDTO.ShardingDSDTO shardingDSDTO = shardingCalDTO.new ShardingDSDTO();
shardingDSDTO.setShardingDbMediaSource(dbDataMediaSource);
shardingDSDTO.setShardingScheme(schema);
shardingDSDTO.setShardingTabele(table);
list.add(shardingDSDTO);
}
}
return shardingCalDTO;
}
|
4).Load阶段改造合并sql适配分片合并;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
private static EventData replaceColumnValue(EventData newEventData, EventData oldEventData) {
List<EventColumn> newColumns = newEventData.getColumns();
List<EventColumn> oldColumns = oldEventData.getColumns();
List<EventColumn> temp = new ArrayList<EventColumn>();
for (EventColumn oldColumn : oldColumns) {
boolean contain = false;
for (EventColumn newColumn : newColumns) {
if (oldColumn.getColumnName().equalsIgnoreCase(newColumn.getColumnName())) {
newColumn.setUpdate(newColumn.isUpdate() || oldColumn.isUpdate());
contain = true;
}
}
if (!contain) {
temp.add(oldColumn);
}
}
for(int i=0;i<newColumns.size();i++){
EventColumn newColumn = newColumns.get(i);
if(newColumn.isReverse()){
boolean bol = false;
for(EventColumn oldColumn:oldColumns){
if(newColumn.getColumnName().equalsIgnoreCase(oldColumn.getColumnName())){
newColumns.set(i,oldColumn);
bol = true;
logger.warn("insert->update 合并反查字段为空,重新设置反查字段 newEventData:{} oldEventData:{}",
newEventData.toString(),oldEventData.toString());
}
}
if(!bol){
newColumns.remove(i);
logger.warn("insert->update 合并反查字段为空,移除该newEventData字段 newEventData:{} oldEventData:{}",
newEventData.toString(),oldEventData.toString());
}
}
}
newColumns.addAll(temp);
Collections.sort(newColumns, new EventColumnIndexComparable());
newEventData.setOldKeys(oldEventData.getOldKeys());
if (oldEventData.getSyncConsistency() != null) {
newEventData.setSyncConsistency(oldEventData.getSyncConsistency());
}
if (oldEventData.getSyncMode() != null) {
newEventData.setSyncMode(oldEventData.getSyncMode());
}
if (oldEventData.isRemedy()) {
newEventData.setRemedy(oldEventData.isRemedy());
}
newEventData.setSize(oldEventData.getSize() + newEventData.getSize());
return newEventData;
}
|
5).在Extract阶段,考虑update语句中数据库反查因查不到数据导致字段为null问题,增加去除null字段;
全量数据迁移支持
原生的otter可以通过自由门来实现全量数据导入和修订功能。
自由门原理如下:
a.基于otter系统表retl_buffer,插入特定的数据,包含需要同步的表名,pk信息。
b.otter系统感知后会根据表名和pk提取对应的数据(整行记录),和正常的增量同步一起同步到目标库。
我们公司业务在改造过程中,涉及到以下痛点:
- 由于原先的otter系统表需要在每一个迁移实例建立retl.buffer表,当迁移的库比较多的时候,需要每个实例分别建立retl库,不利于统一控制,同时给库表元数据管理代理一定的难度;
- 由于全量数据迁移需要手动导入数据,增加迁移复杂度;
改造点
1)增加总控通道,所有的全量数据迁移统一用总控通道;
2)增加全量数据一键导入功能,自动将数据迁移至总控通道;
我们在Select阶段改造,将数据进行分批处理,每批的管道改造同步管道。(统一控制相对单独控制存在一个风险点:如果同步的这批存量数据在Extract阶段后和Load阶段前存在源库数据对应记录的修改,同时修改的增量binlog又比存量同步的数据同步更快,存在数据老数据覆盖新数据的风险,不过这种场景概率极小)
总控全量迁移通道
全量数据迁移任务
1)Select阶段改造
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
|
boolean profiling = isProfiling();
Long profilingStartTime = null;
if (profiling) {
profilingStartTime = System.currentTimeMillis();
}
MDC.put(OtterConstants.splitPipelineLogFileKey, String.valueOf(pipelineId));
String currentName = Thread.currentThread().getName();
Thread.currentThread().setName(createTaskName(pipelineId, "SelectWorker"));
try {
pipeline = configClientService.findPipeline(pipelineId);
List<EventData> eventData = message.getDatas();
long startTime = etlEventData.getStartTime();
if (!CollectionUtils.isEmpty(eventData)) {
startTime = eventData.get(0).getExecuteTime();
}
if (StringUtils.equalsIgnoreCase(RETL_BUFFER, pipeline.getPairs().get(0).getSource().getName())
&& StringUtils.equalsIgnoreCase(RETL, pipeline.getPairs().get(0).getSource().getNamespace())) {
Map<Long, Map<Long,RowBatch>> rowBatchMap = OtterMigrateMap.makeComputingMap(new Function<Long, Map<Long, RowBatch>>() {
@Nullable
@Override
public Map<Long, RowBatch> apply(@Nullable Long channelId) {
return OtterMigrateMap.makeComputingMap(new Function<Long, RowBatch>() {
@Nullable
@Override
public RowBatch apply(@Nullable Long pipelineId) {
RowBatch rowBatch = new RowBatch();
Identity identity = new Identity();
identity.setChannelId(channelId);
identity.setPipelineId(pipelineId);
identity.setProcessId(etlEventData.getProcessId());
rowBatch.setIdentity(identity);
return rowBatch;
}
});
}
});
for (EventData data : eventData) {
EventColumn pipelineColumn = getMatchColumn(data.getColumns(), PIPELINE_ID);
EventColumn channelColumn = getMatchColumn(data.getColumns(),CHANNEL_ID);
if(null == pipelineColumn || null == channelColumn){
logger.error("自由门数据问题,直接跳过,data:{}",data);
continue;
}
RowBatch rowBatch = rowBatchMap.get(Long.parseLong(channelColumn.getColumnValue())).get(Long.parseLong(pipelineColumn.getColumnValue()));
rowBatch.merge(data);
}
Iterator channelIterator = rowBatchMap.entrySet().iterator();
while (channelIterator.hasNext()){
Map.Entry channelEntry = (Map.Entry) channelIterator.next();
Long channelId = (Long)channelEntry.getKey();
Map<Long, RowBatch> rowBatchMaps = (Map<Long, RowBatch>)channelEntry.getValue();
Iterator pipelineIterator = rowBatchMaps.entrySet().iterator();
while (pipelineIterator.hasNext()){
Map.Entry pipelineEntry = (Map.Entry) pipelineIterator.next();
Long pipelineTempId = (Long)pipelineEntry.getKey();
RowBatch rowBatch = (RowBatch)pipelineEntry.getValue();
long nextNodeId = etlEventData.getNextNid();
List<PipeKey> pipeKeys = rowDataPipeDelegate.put(new DbBatch(rowBatch), nextNodeId);
etlEventData.setDesc(pipeKeys);
etlEventData.setNumber((long) rowBatch.getDatas().size());
etlEventData.setFirstTime(startTime);
etlEventData.setBatchId(message.getId());
if (profiling) {
Long profilingEndTime = System.currentTimeMillis();
stageAggregationCollector.push(pipelineTempId,
StageType.SELECT,
new AggregationItem(profilingStartTime, profilingEndTime));
}
arbitrateEventService.selectEvent().single(etlEventData);
logger.info("自由门 分批处理 channelId:{} pipelineId:{} data size:{}",channelId,pipelineTempId,rowBatch.getDatas().size());
}
}
}else {
Channel channel = configClientService.findChannelByPipelineId(pipelineId);
RowBatch rowBatch = new RowBatch();
Identity identity = new Identity();
identity.setChannelId(channel.getId());
identity.setPipelineId(pipelineId);
identity.setProcessId(etlEventData.getProcessId());
rowBatch.setIdentity(identity);
for (EventData data : eventData) {
rowBatch.merge(data);
}
long nextNodeId = etlEventData.getNextNid();
List<PipeKey> pipeKeys = rowDataPipeDelegate.put(new DbBatch(rowBatch), nextNodeId);
etlEventData.setDesc(pipeKeys);
etlEventData.setNumber((long) eventData.size());
etlEventData.setFirstTime(startTime);
etlEventData.setBatchId(message.getId());
if (profiling) {
Long profilingEndTime = System.currentTimeMillis();
stageAggregationCollector.push(pipelineId,
StageType.SELECT,
new AggregationItem(profilingStartTime, profilingEndTime));
}
arbitrateEventService.selectEvent().single(etlEventData);
}
} catch (Throwable e) {
if (!isInterrupt(e)) {
logger.error(String.format("[%s] selectwork executor is error! data:%s",
pipelineId,
etlEventData), e);
sendRollbackTermin(pipelineId, e);
} else {
logger.info(String.format("[%s] selectwork executor is interrrupt! data:%s",
pipelineId,
etlEventData), e);
}
} finally {
Thread.currentThread().setName(currentName);
MDC.remove(OtterConstants.splitPipelineLogFileKey);
}
|
数据校验支持
原生的otter有数据一致性功能,原理是根据binlog延时超过最大阈值,然后通过反查数据库同步获取最新数据 (以数据库最新版本同步,解决交替性,比如设置一致性反查数据库延迟阀值为60秒,即当同步过程中发现数据延迟超过了60秒,就会基于PK反查一次数据库,拿到当前最新值进行同步,减少交替性的问题),业务在改造过程中,涉及以下痛点:
- 源库和目标库不能全量数据校验,导致业务方无法相信迁移数据可靠性;
- 如果出现数据不一致问题,通过人工修复数据流程比较繁琐;
改造点
- 支持全量数据校验,通过比对用主键查询源库和目标库的crc校验码,如果出现不一致则会重试3次,最终落库;
- 根据全量数据校验查询到的不一致数据,通过全量任务触发来修复数据不一致;
脱敏数据改造
原生的otter在数据安全方面做的比较差,业务在改造过程中,涉及到以下痛点:
- 匿名用户可以查看所有同步任务进度和数据库实例的信息;
- 数据库实例账号密码明文存储;
改造点
- 数据库账号密码采用密文存储;
- manager管理端改造权限,分为管理用户和普通用户;管理用户具有最高权限;普通用户只能查看任务的基本信息、同步进度和日志等;
- manager管理端数据库连接改造接入pk;