数据平滑迁移方案
数据迁移方案
数据迁移核心思路抽象起来其实很简单,但如何稳定平滑迁移数据,我们会遇到不少问题,如:
- 数据如何迁移?
- 如何校验数据迁移过程中的正确性?如果发现数据不一致,如何修复?
- 我们的业务改造有问题如何回滚?
数据同步中间件选型
开源数据同步中间件主要包括canal、otter、maxwell、kettle等,下面进行简单比对说明。
- canal:canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL。
- otter:阿里巴巴旗下的另一款开源项目,始于中美数据同步需求,纯Java开发。可以理解为canal+ETL,对数据抽取进行了扩展,加入自由门、反查等功能,拓展了已经无法从binlog获取的数据来源。同时提供页面的ETL编辑配置功能,方便快速实现带逻辑的业务数据同步。
- maxwell:Maxwell 是java语言编写的能够读取、解析MySQL binlog,将行更新以json格式发送到 Kafka、RabbitMQ等,有了增量的数据流,可以想象的应用场景实在太多了,如ETL、维护缓存、收集表级别的dml指标、增量到搜索引擎、数据分区迁移、切库binlog回滚方案等等。
- kettle:kettle可以实现从不同数据源(excel、数据库、文本文件等)获取数据,然后将数据进行整合、转换处理,可以再将数据输出到指定的位置(excel、数据库、文本文件)等;是B/S架构,多用于数仓作业。
最终结合公司需求,otter功能最强大,二次开发比较方便,最终选择用otter来作为数据同步工具。
重点原理阐述
全量迁移:数据迁移首要目标如何将历史全量数据迁移到新库中,我们利用otter的自由门原理改造支持全量数据同步功能,整个过程都是查询在线库的备库,因此不影响在线业务的数据库服务,自由门原理如下:
a. 基于otter系统表retl_buffer,插入特定的数据,包含需要同步的表名,pk信息。
b. otter系统感知后会根据表名和pk提取对应的数据(整行记录),和正常的增量同步一起同步到目标库。
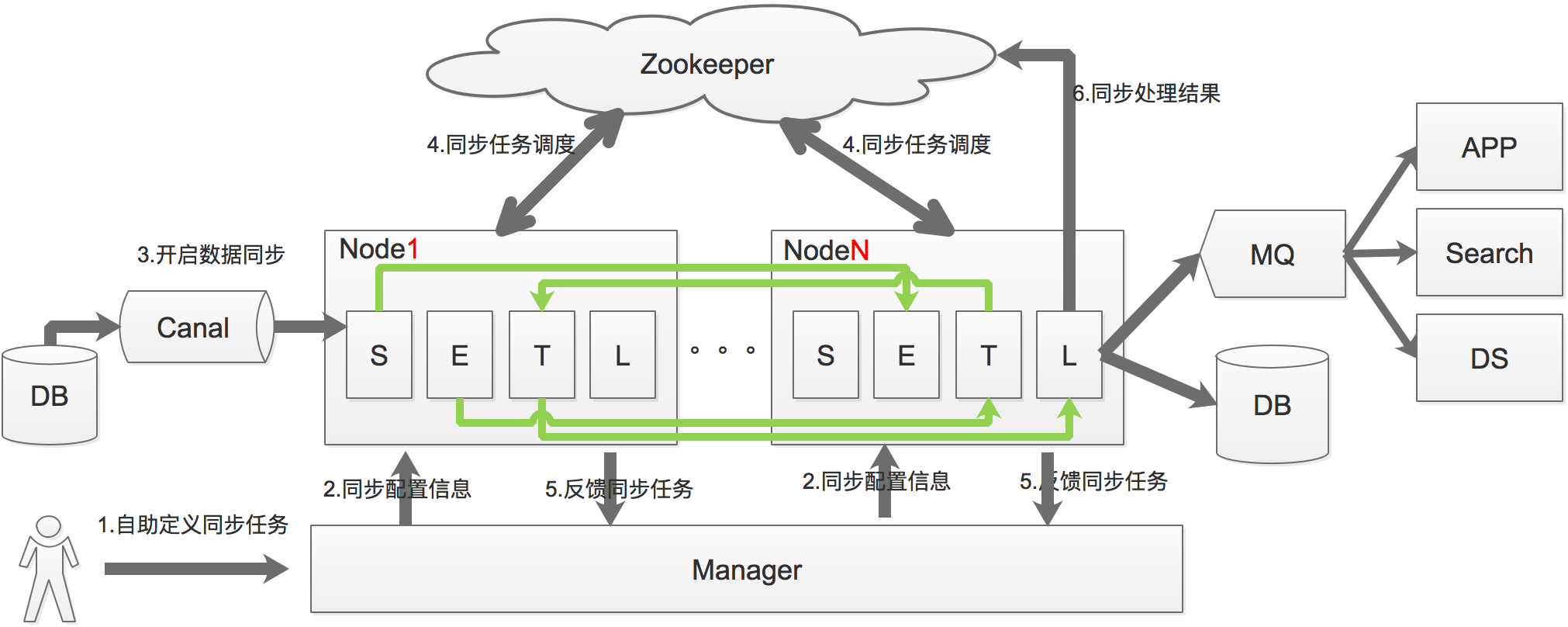
增量迁移:通过模拟mysql slave获取binlog数据,然后通过canal解析增量数据,最终准实时同步数据。
方案一:先开启全量任务,等全量数据同步完成后,在开启增量任务。由于迁移过程中业务服务一直运行,因此全量迁移完全成,并且要将全量时间点后的数据追回来,这里核心原理是同步全量时间位点后binlog日志数据来保证数据一致性,需要注意的是增量时间需要前移一小断时间(如5分钟),其主要原因是全量迁移启动的那刻会有时间差,需要增量前移来保证数据最终一致性。
方案二:先开启增量任务,然后开启全量任务,这种方案存在当全量和增量任务同时操作同一条pk数据的时候,就可能会产生丢失更新。推荐使用该方案,操作比较简单,这种场景出现的问题是很小的概率,最终还能通过数据校验服务来找到问题数据,然后用一键修复功能即可。
增量同步原理如下:
a. 基于Canal获取数据库增量日志数据。
b. 利用SETL调度模型实现调度和处理实现。
c. 基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作。
工作原理如下:
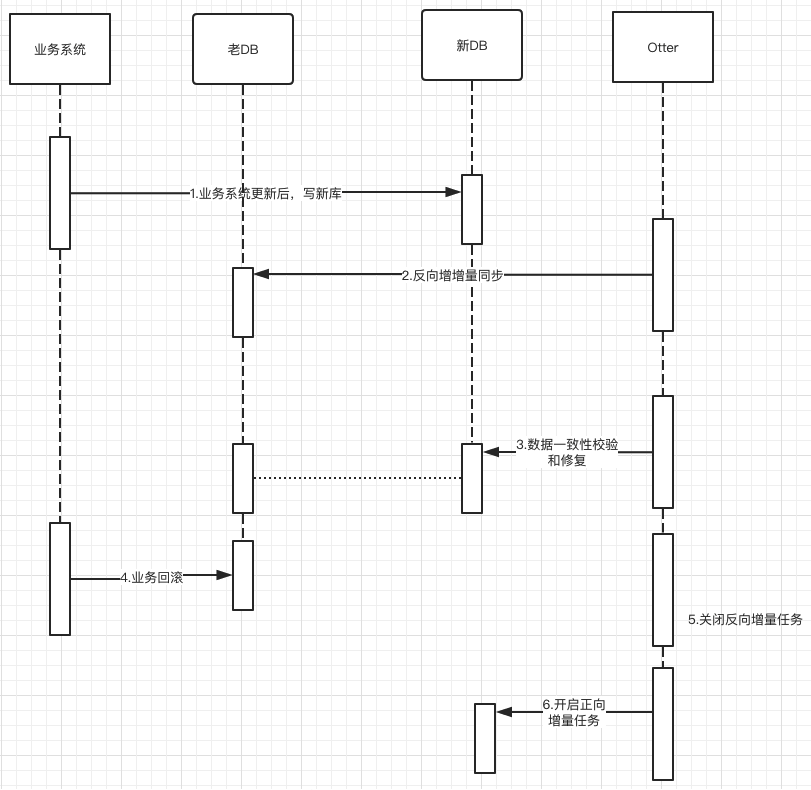
反向同步:迁移到新库后,为了保证业务方出现业务回滚,保证源库与目标库数据一致性,需要建立从新库到老库的回流任务,原理跟增量迁移一样,只是变更一下原库及目标库。
一致性校验:通过比对源库和目标库的所有同步字段的crc校验码,如果出现不一致,重新比对3次,如果最终数据不一致,则会将该条数据落库。流程图如下:

一键修复:将一致性校验比对失败的数据,通过全量同步原理来触发数据修复功能。
项目分库分表实施总体方案
实现方案
- 业务系统改造和测试:业务方接入sharding-jdbc和分布式主键中间件,然后验收测试改造功能;
- 数据迁移:利用otter的数据迁移功能,涉及到全量迁移、增量迁移、一致性校验及反向任务。
迁库流程
事先一定创建好增量任务、全量任务、逆向任务和一致性校验任务等操作,然后如下操作:
- 开启Otter增量同步,然后开通全量同步;
- 系统切换前做数据一致性校验,如若发现数据不一致,通过一键修复来修复数据;
- 业务系统升级;
- 升级完成后,同时关闭增量同步任务,防止无效覆盖;
- 反向同步任务要清空位点信息和手动设置canal位点信息,时间戳为关闭增量的时间,最后开启反向同步任务,数据回流老库;
问题点:
如何保证全量任务已同步完成?
通过查看”总控通道”的最后位点时间如果一直没更新,就表示全量任务同步完成;目前由于全量数据量不可控制,推荐根据历史时间推算或者按照全量数据24小时之后来表示全量同步完成(通过线下环境测试,全量数据大概1分钟可以导入19w左右);
如何保证在开启反向任务之后,新库同步到老库数据丢失问题?
在关闭正向同步之后,开启反向同步前,为了防止数据丢失,将反向同步的canal位点信息前移一段时间(停止正向增量任务的时间);注意位点可以直接指定时间戳,如:{“journalName”:””,”position”:0,”timestamp”:1559628000000};
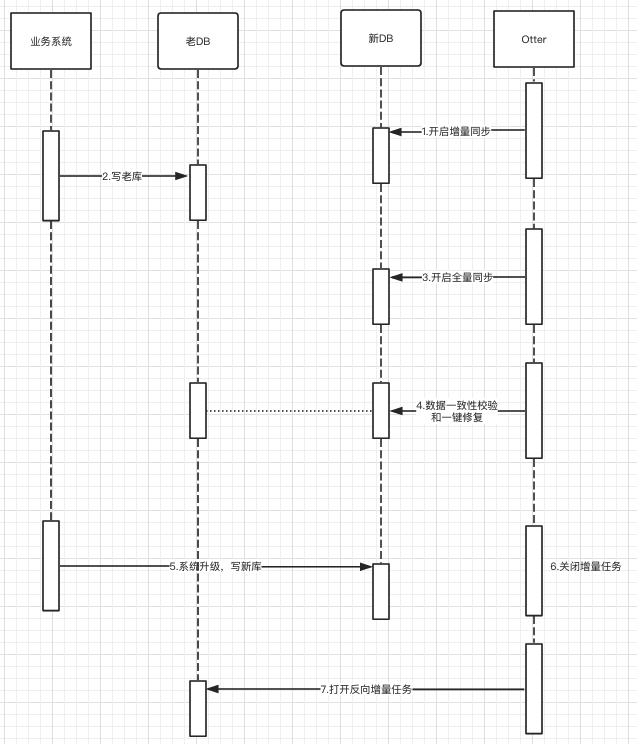
回滚方案
事先一定创建好逆向一致性校验任务等操作,然后如下操作:
- 系统切换前做反向数据一致性校验,如若发现数据不一致,通过一键修复来修复数据;
- 业务系统回滚;
- 回滚完成后,同时关闭逆向增量任务;
- 正向同步任务要清空位点信息和手动设置cancal位点信息,时间戳为关闭逆向增量任务的时间,最后开启正向同步任务;
问题点:
业务一旦发生问题,一定要快速回滚,如何保证在短时间内能校验老库数据是一致的?
针对需要快速校验和修复,同步前推荐业务方的同步表需要有”更新时间”字段,该字段最好有索引字段,这样既可以在校验服务中加入用”更新时间”的过滤条件,这样就可以不用全库校验,只校验这段时间内更新的数据;
由于业务是在回滚完成之后,然后在开启正向增量同步,存在这段时间过程中的丢失更新?
在关闭反向同步之后,开启正向同步前,为了防止丢失数据,将正向同步的canal位点信息前移一小断时间(停止反向同步的时间);注意位点可以直接指定时间戳,如:{“journalName”:””,”position”:0,”timestamp”:1559628000000};